
Ethan Jewett
Scientist and product developer. I design algorithms and consumer features to help people understand their personal genetic data. I have a PhD in Biosciences from Stanford University and a master's degree in applied mathematics from the University of Michigan.
Last updated: May 17, 2026
Products
Reconstructed Ancestors
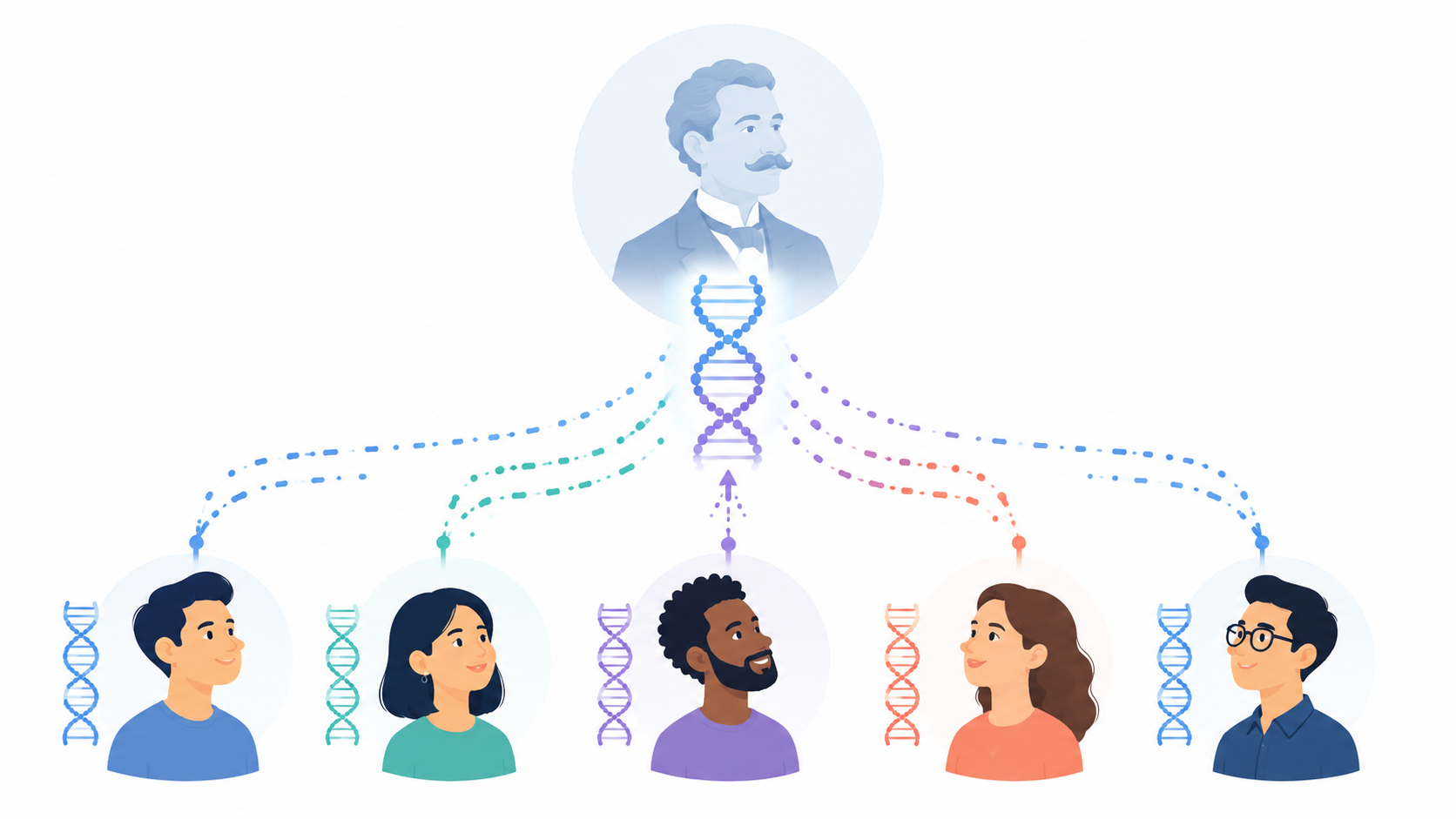
Want to learn more about one of your ancestors by sequencing their DNA (e.g., from a hair sample)? I turns out you don't have to. We can statistically reconstruct their genome using DNA from you and your relatives. My work on ancestor reconstruction has become the Reconstructed Ancestors product feature at 23andMe, powered by my GRAMPA algorithm (Genotype Reconstruction and Ancestral Mixture Proportions in Ancestors).
The 23andMe Family Tree
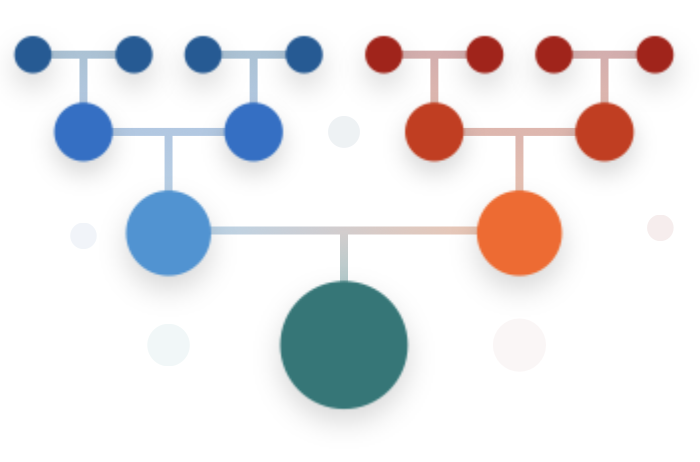
Personal genomics companies like 23andMe and Ancestry.com can detect your relatives in their databases. These relatives are ususally presented in a list of relationships (e.g., "Bob Smith: 2nd Cousin"). My Bonsai algorithm allows you to see how all these people fit together in a family tree. This became the 23andMe Family Tree feature.
Distant Relationships
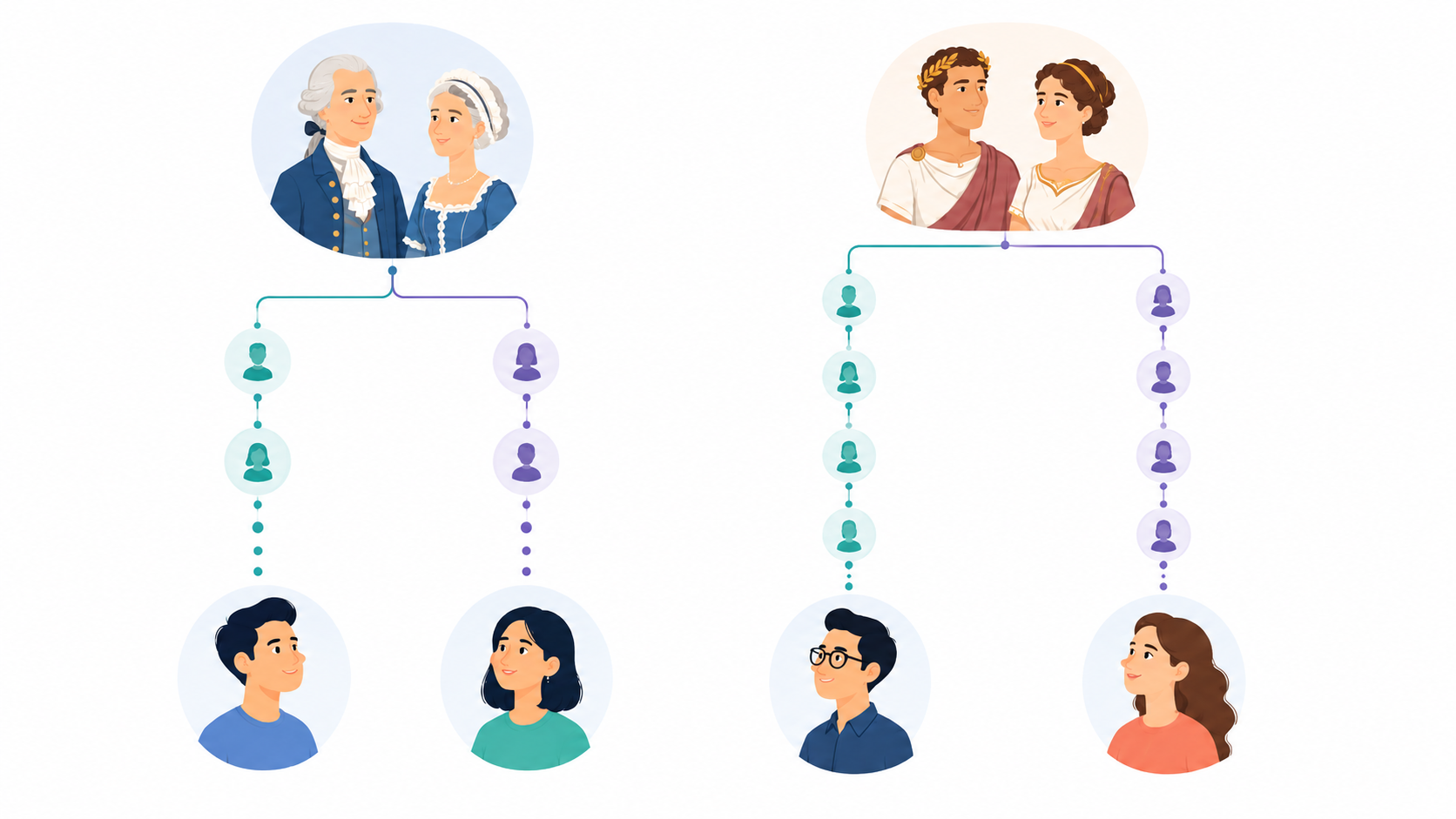
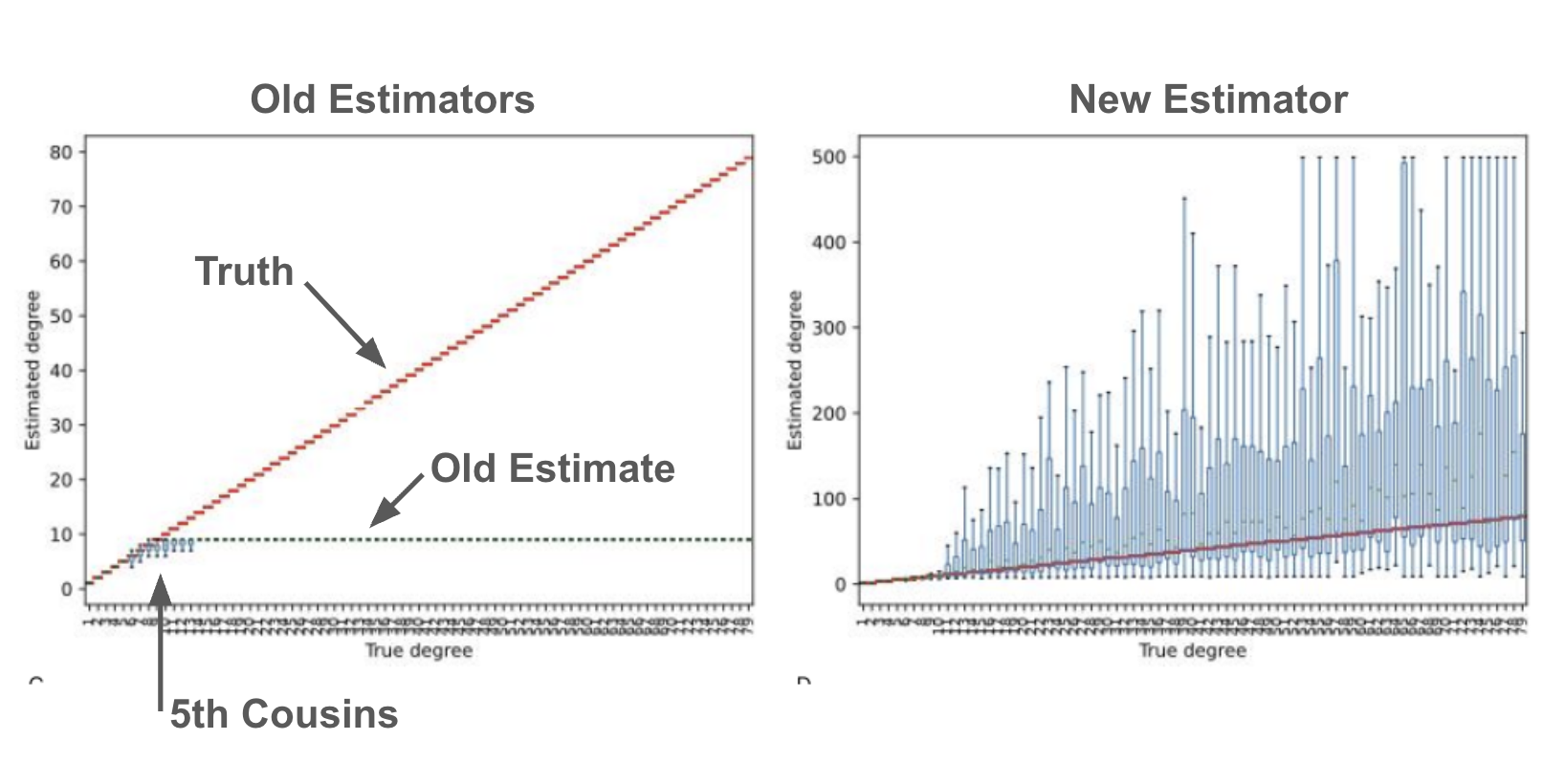
For over a decade, genomics companies and researchers have estimated relationships incorrectly. It was believed that the most distant relationship one could detect from genetic data was around a 5th cousin. I noticed this mistake and created a correct estimator. The new estimator shows that the majority of relationships are much more distant than previously thought. For instance, some previously predicted 6th cousins might be more like 100th cousins, sharing common ancestors with one another in Roman times, rather than in the 18th Century. These relationships now power our DNA Relatives product feature. Read my paper on the new estimator.
23andMe Surname Pages
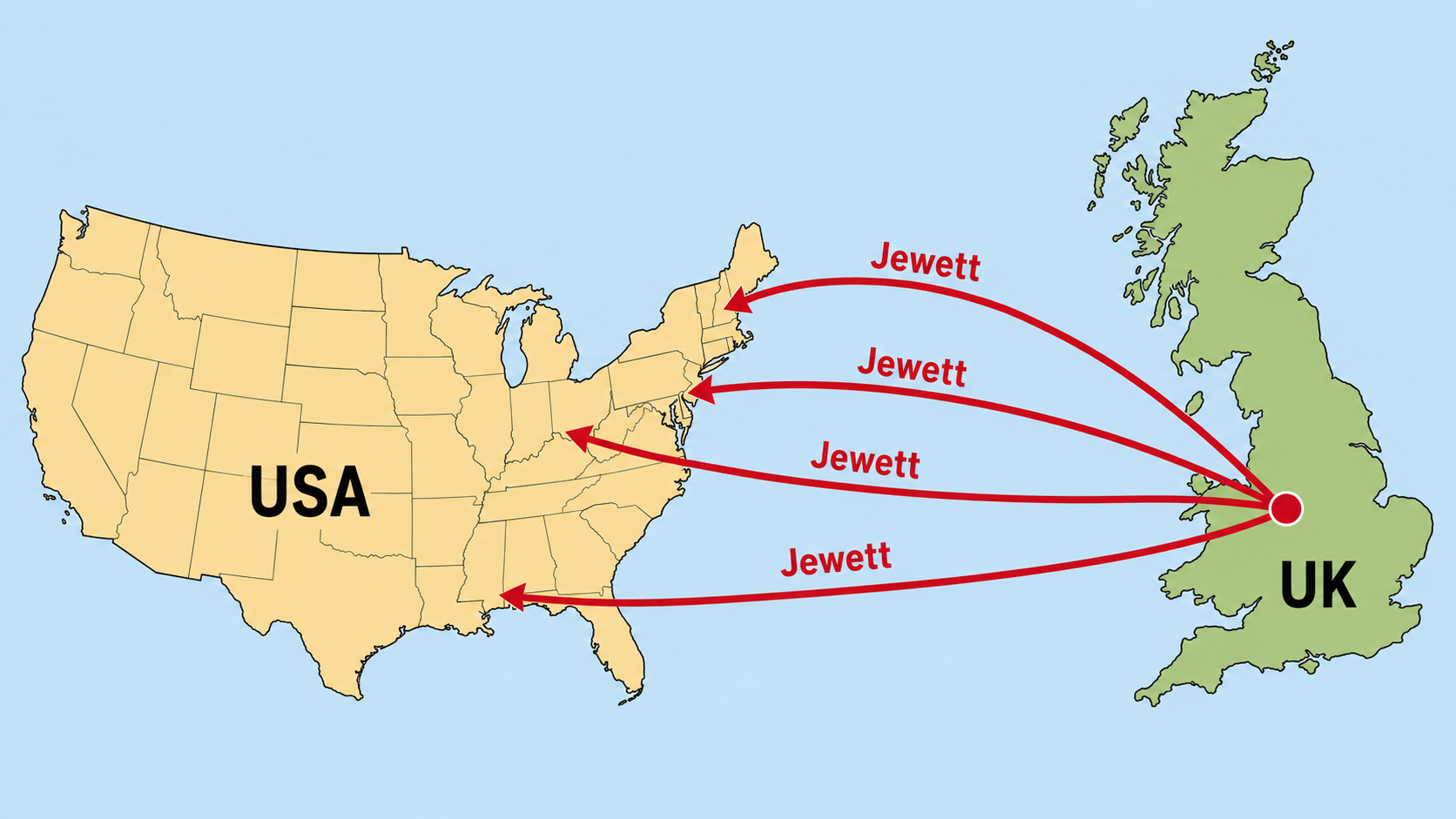
At 23andMe I was tasked with creating a set of public facing pages that allow customers to learn about genetic patterns linked to their surnames.
Selected Research Projects
Identifying historical burials

In a recent study of burials from colonial Maryland, we used genetic pedigree inference, genealogy and isotopic data to propose identities for three unmarked burials including the first governor of Maryland, Thomas Greene, his son Leonard, and his wife Anne Cox. To our knowledge this is the first time that genetics has been used to re-identify the remains of historical figures without any prior hypothesis about their identities. Read the summary in Discover Magazine or Popular Science.
Restoring genealogical ties severed by slavery

Slavery in America left millions of people disconnected from their ancestral roots. By finding genetic connections with historical burials of enslaved workers at Catoctin Furnace in Maryland, we were able to connect them to their modern descendants, restoring connections that had been lost. Check out news coverage by the New York Times and NPR
Fixing Relationship Estimates
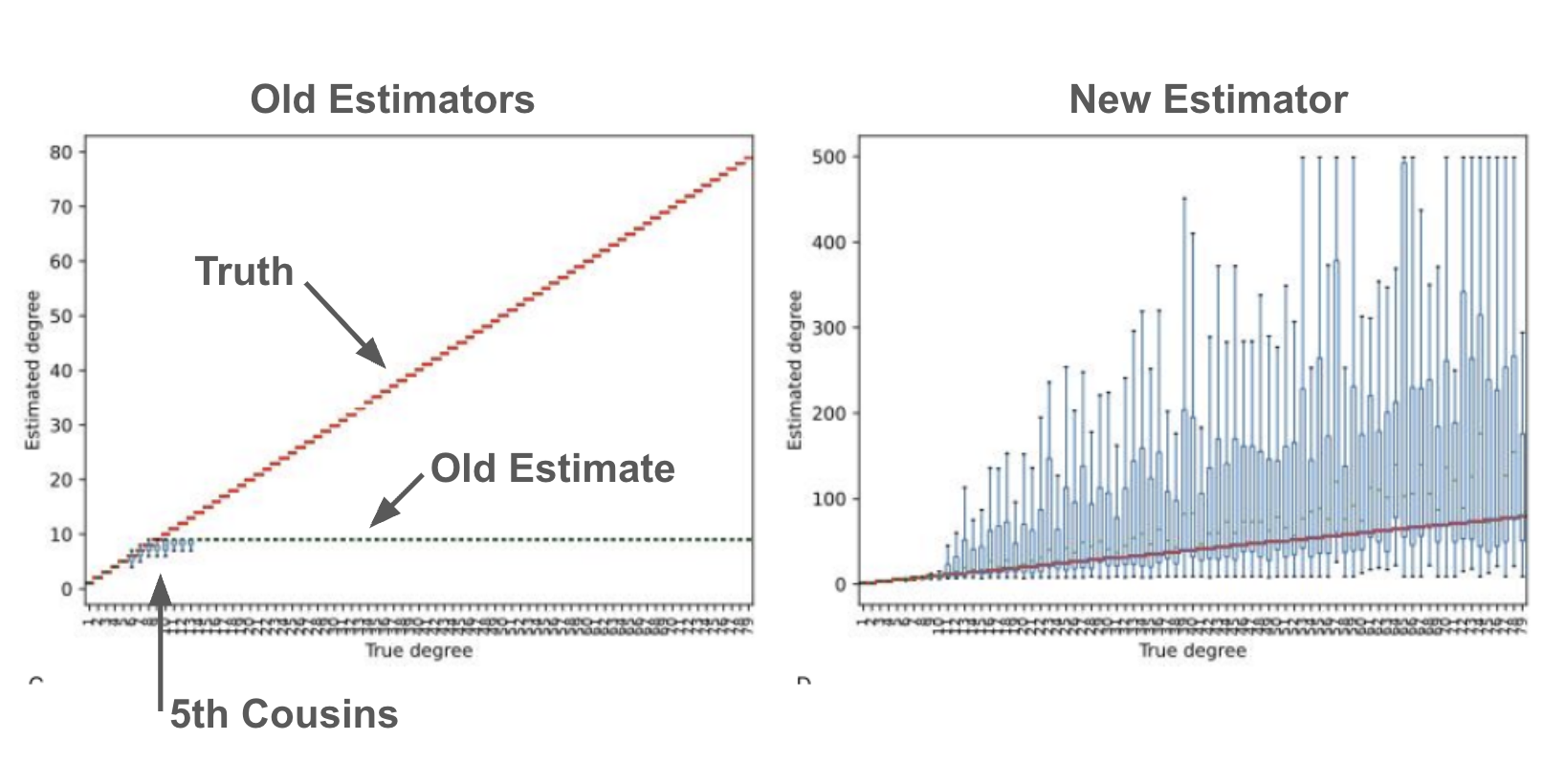
Academic researchers and genetic testing companies have been incorrectly applying relationship esimators for the better part of two decades. This has led everyone to believe erroneously that the most distant relationship that can be detected from genetic DNA sharing is around a 5th cousin (the chances of sharing DNA with a more distant relative become vanishingly small under the current models). But these models ignore the fact that each person is related to every other person through millions of different ancestors, making the chances of sharing DNA with a distant cousin very high. I noticed this mistake and derived new relationship estimators. These new estimators push the most distant detectable relationship out to cousins separated by hundreds of generations, not five generations as previously thought.
Deterministic approximations to the Coalescent Model
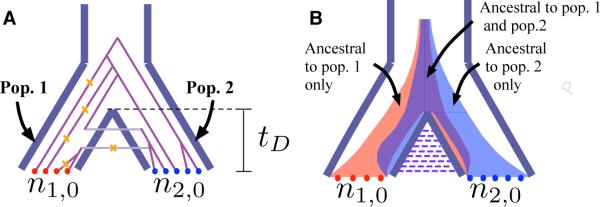
The Coalescent Model is a fundamental framework in genetics for understanding the evolutionary history of genetic lineages. Many formulas can be derived under this model, such as the expected time when two pieces of DNA share a common ancestor or the distribution of allele frequencies in a population. However, derived quantities under the model can have complicated closed forms and algorithms that implement these formulas can be slow. Deterministic approximations to the model have been known for decades, but each author largely rediscovered them anew and there was no formalism to understand their accuracy or broad principles of usage. I put these approximations on a firm theoretical footing by showing when they are accurate and I compiled the first systematic treatment of how to apply them.
Patents
Genome Phasing
26-0135-US-PRO (pending)
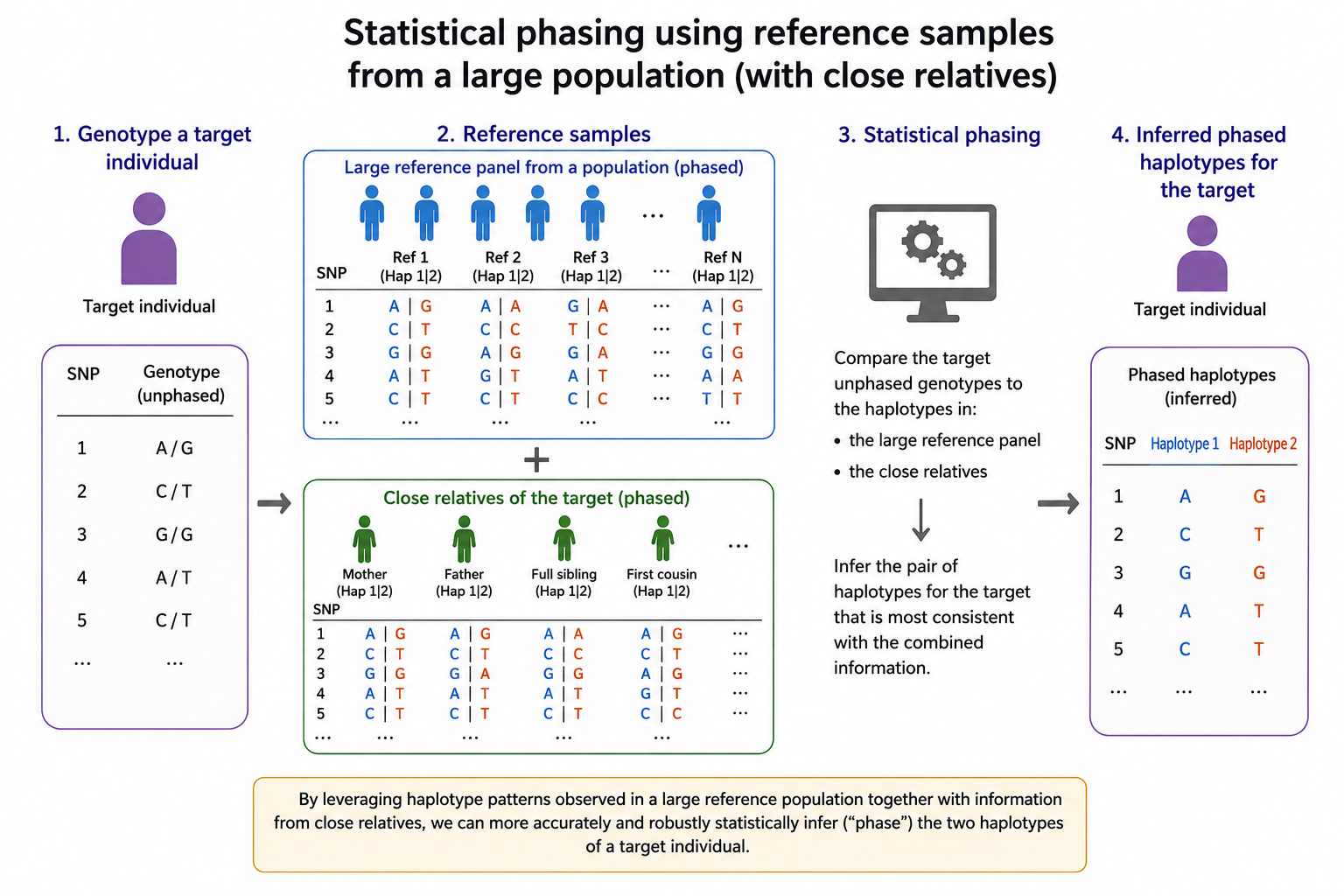
You inherit one copy of your genome from your mother and another copy from your father. However, the information about which allele came from which parent is lost in genome sequencing and genotyping. "Phasing" is a technique for recovering the parental side information about alleles. Most phasing methods compare a focal genome to the genomes of thousands of very distant relatives. However, by leveraging close relatives of the person we want to phase (so-called Family Phasing), we can do a better job. A patent application for my method for family phasing is currently pending.
Pedigree Inference
US11514627B2 (granted 2022)
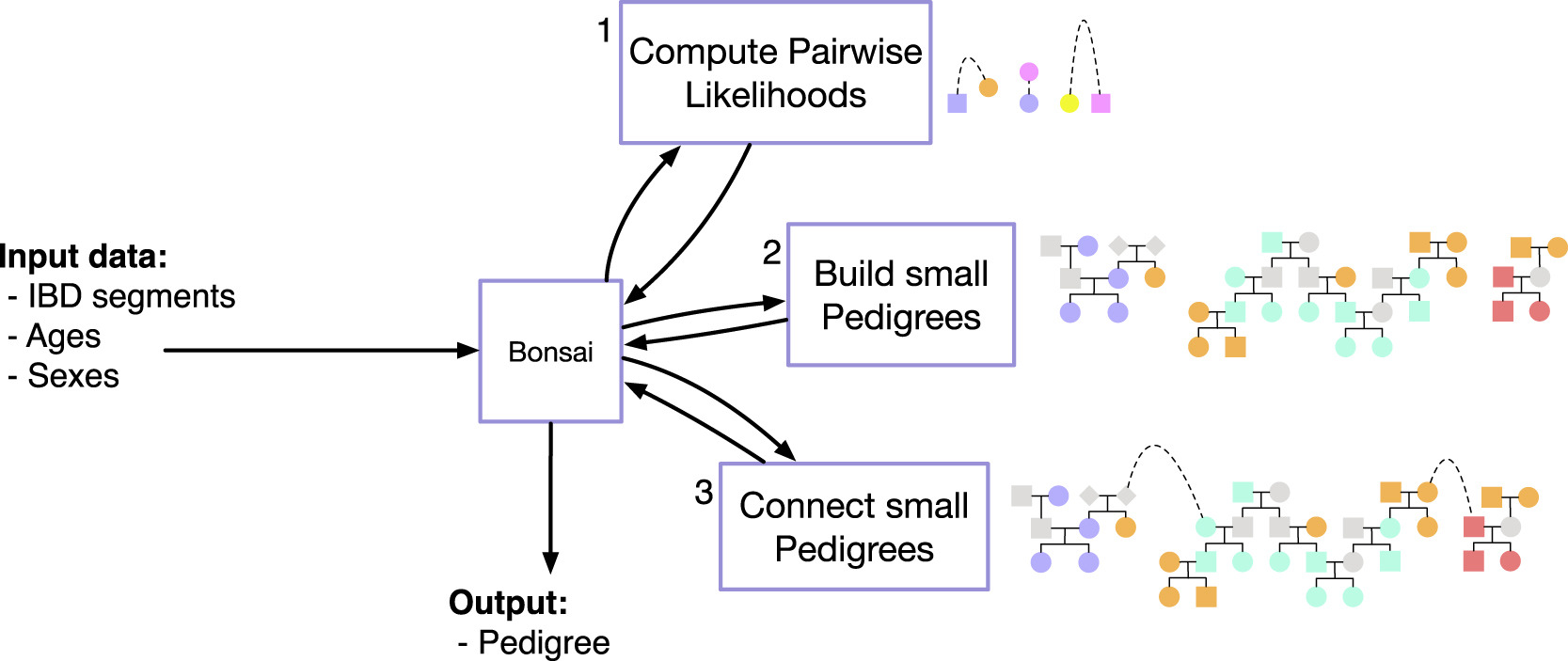
Family trees are typically built by hand using laborious trial and error methods. In the last decade, several computational methods have been developed to infer pedigrees. My Bonsai method is the current state of the art method for inferring large complicated pedigrees. See the Bonsai paper here.
Conditional Relationship Inference
24-0612-US-PRO2 (pending)
This patent covers relationship infrence methods that correctly infer distant relationships, fixing a mistake that has existed in the scientific literature for over a decade and greatly extending the most distant relationship that can be inferred. This patent also introduces methods for sampling DNA sharing within pedigrees, conditional on the event that individuals in the pedigree share DNA.
Other Patents
- US11817176B2 (granted 2023): Ancestry composition determination.
- US12046327B1 (granted 2023): Identity-by-descent relatedness based on focal and reference segments.
Publications
Historical Pedigree Inference
- Harney É, Jewett EM, Micheletti S, et al. (2026). The genetic legacy of the 17th-century colonial capital of St. Mary's City. Current Biology.
- Harney É, Micheletti S, Bruwelheide KS, Freyman WA, Bryc K, Akbari A, Jewett EM, et al. (2023). The genetic legacy of African Americans from Catoctin Furnace. Science 381:eade4995.
Pedigrees
- Jewett EM, McManus KF, Freyman WA, Auton A (2021). Bonsai: An efficient method for inferring large human pedigrees from genotype data. American Journal of Human Genetics 108:2052-2070.
- Jewett EM and The 23andMe Research Team (2024). Simulating pedigrees ascertained on the basis of observed IBD sharing. bioRxiv 2024.05.13.594012.
- Jewett EM and The 23andMe Research Team (2024). Correcting model misspecification in relationship estimates. bioRxiv 2024.05.13.594005.
IBD
- Freyman WA, McManus KF, Shringarpure SS, Jewett EM, Bryc K, et al. (2021). Fast and robust identity-by-descent inference with the templated positional Burrows-Wheeler transform. Molecular Biology and Evolution 38:2131-2151.
- Williams CM, O'Connell J, Freyman WA, Jewett EM, Gignoux CR, Ramachandran S, Williams AL (in prep.). Phasing millions of samples achieves near perfect accuracy, enabling parent-of-origin classification of variants.
- Qiao Y, Jewett EM, McManus KF, Freyman WA, et al. (2024). Reconstructing parent genomes using siblings and other relatives. bioRxiv 2024.05.10.593578.
Coalescent Theory
- Jewett EM (2020). Fast and accurate approximation of the joint site frequency spectrum of multiple populations. bioRxiv 2020.05.01.073213.
- Jewett EM, Steinrücken M, Song YS (2016). The effects of population size histories on estimates of selection coefficients from time-series genetic data. Molecular Biology and Evolution.
- Steinrücken M*, Jewett EM*, Song YS (2016). SpectralTDF: transition densities of diffusion processes with time-varying selection parameters, mutation rates, and effective population sizes. Bioinformatics 32:795-797.
- Jewett EM, Rosenberg NA (2014). Theory and applications of a deterministic approximation to the coalescent model. Theoretical Population Biology 93:14-29.
- Jewett EM*, Zawistowski M*, Rosenberg NA, Zöllner S (2012). A coalescent model for genotype imputation. Genetics 191:1239-1255.
- Helmkamp L, Jewett EM, Rosenberg NA (2012). Improvements to a class of distance matrix methods for inferring species trees from gene trees. J. Comput. Biol. 19:632-649.
- Jewett EM, Rosenberg NA (2012). iGLASS: An improvement to the GLASS method for estimating species trees from gene trees. J. Comput. Biol. 19:293-315.
Miscellaneous
- Jewett EM, Någren K, Mock BH, Watkins GL (2023). 30 years of [11C]methyl triflate. Appl. Radiat. Isot. 197:110812.
- Verdu P*, Jewett EM*, Rosenberg NA, Baptista M (2017). Parallel trajectories of genetic and linguistic admixture in a genetically admixed creole population. Current Biology 27:2529-2535.
- Crawford NG, et al. (2017). Loci associated with skin pigmentation identified in African populations. Science 358(6365).
- Shen Y, Thompson DL, Kuah M, Wong K, Wu KL, Linn SA, Jewett EM, Shu-Chien AC, Barald KF (2012). The cytokine macrophage migration inhibitory factor (MIF) acts as a neurotrophin in the developing inner ear of the zebrafish, Danio rerio. Developmental Biology 1:84-94.
- Borràs E, Pineda M, Blanco I, Jewett EM, et al. (2010). MLH1 founder mutations with moderate penetrance in Spanish Lynch syndrome families. Cancer Res. 70:7379-7391.
- Rosenberg NA, Huang L*, Jewett EM*, Szpiech ZA*, Jankovic I*, Boehnke M (2010). Genome-wide association studies in diverse populations. Nat. Rev. Genet. 11:356-366.
Experience
Senior Scientist I, Population Genetics R&D
23andMe, Sunnyvale, CA | 2017 - Present
Research and development of population-genetics methods powering consumer features at 23andMe, including pedigree inference (Bonsai), identity-by-descent inference, relationship estimation, family phasing, and ancestry composition.
Postdoctoral Researcher
UC Berkeley, Departments of Statistics and EECS | 2014 - 2017
Postdoctoral research in statistical population genetics, including approximations to the joint site frequency spectrum of multiple populations and methods for inferring selection coefficients from time-series genetic data.
PhD Student Researcher, Biosciences
Stanford University, Department of Biology | 2011 - 2014
PhD research on coalescent theory and population-genetic inference. Recipient of the Samuel Karlin Prize in Mathematical Biology and the CEHG Predoctoral Fellowship in Genomics.